This blog is going to start what will likely be a long-running series of blogs spread over several months, and digging into the details of next-generation applications, services, and network infrastructures. There are many dimensions to that problem, and as is often the case, the industry has attacked it from the bottom. As is also often the case, that’s not the best approach. The future of both applications and networks is tied to virtualization, and virtualization is about…well…things that aren’t quite real at one level. Those things, of course, have to be made real or networks become fiction, and so we really need to start our discussions of the future with an exploration of that boundary between the not-quite-real and the real.
I’ve noted in past blogs that the boundary between applications/services and resources is an important if hazy place. In virtualization, resources are elastic and assigned dynamically, moving and scaling as required. Since application elements are also dynamic, this means that the boundary between the two is almost tectonic in nature, with the same kind of possible negative consequences when things slip too much.
One particular issue that’s arising at the boundary is that of addressing. Applications and services are built from components that have to be addressed in order to exchange information. For decades, we’ve recognized that one of the issues in IP is the fact that an address has two different meanings, and virtualization is pulling that issue to the forefront. It’s the addressing of application components and resource points that creates that boundary tension I’ve noted above. If you can’t make addressing work, you can’t make any form of virtualization work either.
Let’s suppose you’re a user of an application we’ll call “A1”. You would likely access that application through a URL, and we’ll assume the URL has the same name as the application. That’s clearly a logical address, meaning that you don’t care where A1 is, only that you want to get to it. When you click on the URL, a domain name server (DNS) decodes the URL name to an IP address, and this is where things go sideways. The IP address identifies A1 as a network location, because when a packet is sent to A1 it has to go somewhere specific in the network. We have transitioned, perhaps unknowingly, from a logical address reference (the URL) to a physical network reference (the IP address).
OK, you might be thinking, so what? If our IP address is in fact the address of A1, we get packets to it regardless of how we split hairs on what the IP address represents. And in the old days of fixed hosting of applications, that was indeed fine. Think now of what happens with virtualization. Let’s look at a couple of scenarios.
Scenario one is that the host where A1 lived fails, and we redeploy it to another host. My conception of A1 doesn’t change, but now packets have to go to a different IP address to get to A1. At the least, I have to update my DNS to reference it correctly. I may also have to tell my client systems to “poison their DNS cache”, meaning stop using a saved address for A1 and go back to the DNS to get a new one. I may also have to reflect the change in A1’s address in any firewall or forwarding rules that depended on the old address. In short, I might have created a bunch of issues by solving a single problem of a failed host.
Scenario two is where so many users are hammering at A1 that I decide to scale it. I now have two instances of A1, but my second instance will never get used because nobody knows about it. So, I update the DNS, you say? Sure, but in traditional DNS behavior that only redirects everything to the second instance. I add a load balancer? Sure, but that load balancer now has to be where the DNS points for everyone, and the load balancer then schedules the individual instances of A1. I have the same issues as my first scenario as far as firewalls and forwarding and DNS updates. I get the same issues again if I drop one instance and go back to my one-address-for-A1 model.
Not tired yet? OK, imagine that in either of these scenarios, I’ve used the public cloud as an elastic resource. I now have to expose a public cloud address of A1 through an elastic address or NAT translation of the IP address, because the cloud provider can’t be using my own IP address space directly. Now not only does my IP address change, I have an outlier IP address (the one the public cloud exposed) that has to be routed to the cloud provider’s gateway with me, and that has to work with firewalls and forwarding rules too.
Let’s stop scenarios and talk instead of what we’d like. It would be nice if the IP address space of a business contained only logical addresses. A1 is A1 in IP address terms, whether it’s in or out of a cloud, whether it’s a single instance or a thousand of them, and whether it’s moved physically or not. I’d like to be able to define an IP address space for my business users and their applications that would reflect access policies by address filtering. I’d like to do the same on the resource side, so my hosted components could only talk with what they’re supposed to. This is the challenge of virtualization in any form, meaning the cloud, containers, VMs, SD-WAN, whatever.
Mobile users pose challenges too, in a sense in the opposite direction. A mobile user that moves among cells will move away from where their IP address is pointing, meaning that traffic would be routed to where they were when the address was assigned, not to where they currently are. This problem has been addressed in mobile networks through the mobility management system and evolved packet core (MMS and EPC), which use tunnels that can be redirected to take traffic to where the user actually is without changing the address of the user. This is a remedy few like, and there’s been constant interest in coming up with a better approach, even within 5G.
What approaches have been considered? Here’s a high-level summary of things that might work, have worked, or maybe somebody hopes would work:
- Address translation. Almost everyone today uses “private IP addresses” in their home. Their home networks assign addresses from a block (192.168.x.x) and these addresses are valid within the home. If something has to be directed outside, onto the Internet, it’s translated into a “real” public IP address using Network Address Translation (NAT).
- DNS coordination. In my example above, a DNS converted “A1” as a URL to an IP address. If we presumed that every resource addressable on an IP network was always addressed via a DNS, then updating the DNS record would always connect a user to a resource that moved.
- Double Mapping. A DNS record could translate to a “logical IP address” that was then translated into a location-specific address. This has been proposed to solve the mobile user problem, since the user’s “second” address could be changed as the user moved about.
- Overlay address space. An overlay network, created by using tunnels to link “virtual routers” riding on a lower-level (presumably IP) network, could be used to create private forwarding rules that could be easily changed to accommodate moving applications and moving users. Some SD-WAN vendors already do “logical addressing”. Mobile networks use MMS/EPC, as already noted, for tunnel-based user addressing.
- Finally, the IETF has looked at the notion of using one address space (IP, in most cases) over what they call a “non-broadcast multi-access network” or NBMA, which provides a codified way of what could be called “who-has-it” routing. A network entry point contacts exit points to see who has a path to the addressed destination.
All of these approaches look at the problem from the network side, and in my view they all have potential but with the collateral problem of complexity of implementation. What everyone tells me is that they want to see an architected approach that simplifies the problem, not just a solution that network geeks might be able to adopt.
What would such a solution look like? The simplest way to resolve the problems I’ve cited here is the “god-host” solution. Imagine a giant universal server that hosts everything. Now you have no confusion about addressing or location because everything is in the giant host. Before you start imagining some movie monster or sinister robot, we can add in the word “virtual” to sanitize the approach. A “virtual server” that envelops the network itself and directly connects to users would have none of the complexities described in the scenario. It might adopt some, all, or none of the network strategies outlined above, but nobody would have to worry about that part.
The figure HERE illustrates how such a solution might appear. The “cloud” houses a bunch of diverse, anonymous resources that might be hosted in a single megadatacenter, a bunch of edge data centers, or any combination thereof. They might be bare metal, virtual machines, containers, or (again) any combination of the three. Inside, you might want to collect some of the resources into subnetworks or clusters to reflect a need for inter-component addressing. NFV pools would be like that. Outside, you could have any number of different addressing schemes to define users and applications.
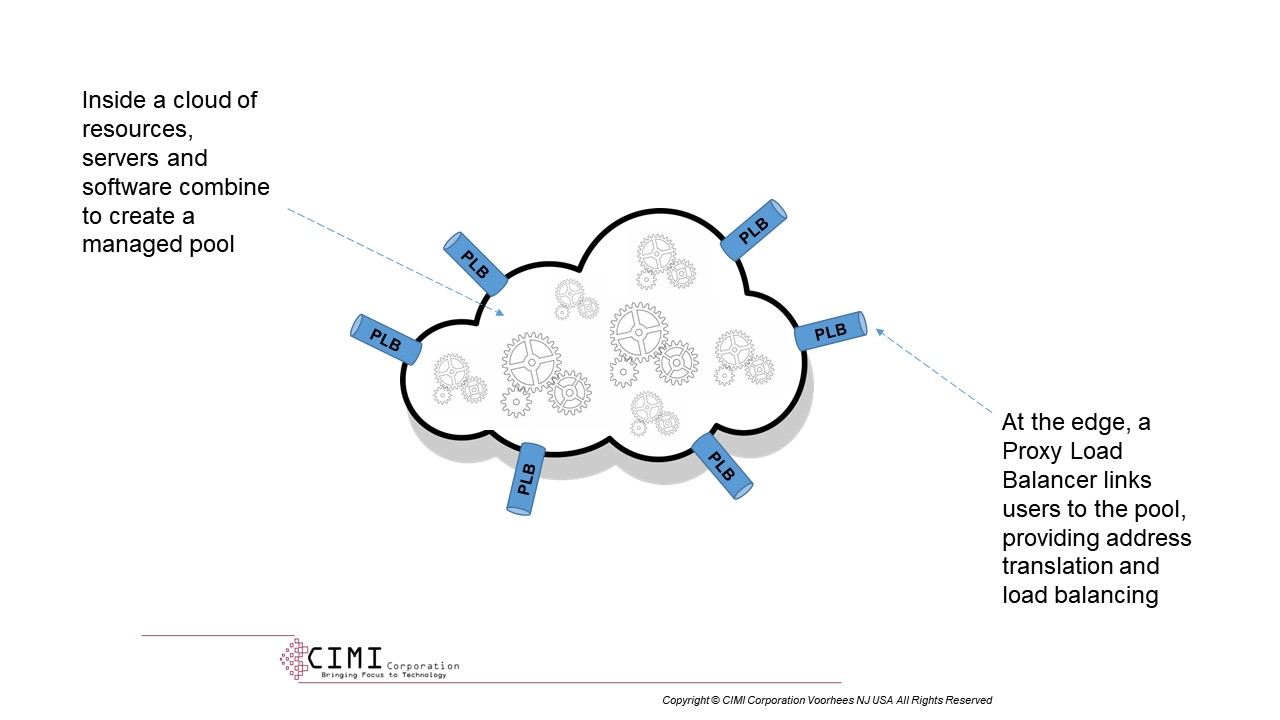{kind=link}
The secret sauce here is the boundary layer, created by what the figure calls a “Proxy Load Balancer”. This is a kind of adapter that, on the user side, presents an address in the user’s address space that represents a logical feature or application. On the resource side, it provides a load-balanced connection to whatever in-the-cloud resources happen to fulfill that feature/application at the moment. If we assume that this capability exists, then we can spread a unified application fabric over every user, and a unified resource fabric over every cloud and data center. Without it, the interdependence between logical and physical addressing will complicate things to the point where there’s no practical way of realizing the full potential of virtualization.
The question is whether we can provide the pieces of this model, and I’m going to look at some strategies to do that. The first is a set of open-source elements that are collectively known as “DC/OS” for “data center operating system”. This builds on the exploding popularity of containers, but it also provides what may well be the best solution for resource virtualization that’s currently available. I’ll try to get to it later this week, or if not the following week. Other blogs in this series will follow as I gather the necessary information.