What can we learn from 3Q20 earnings? Company reports on revenue and earnings often provide us with important information about the real market trends, not the hype trends we so often read about. There were high hopes for this quarter from many companies, but did they pan out? What can we read from the results that tells us what’s happening with the cloud, with 5G, and with the market overall?
Let’s start with the big network operators in the US, AT&T and Verizon. Both operators suffered revenue losses in the latest quarter, with AT&T’s 9% drop outpacing Verizon’s 5% loss. Both companies are maintaining reasonable performance given the pandemic, but neither is seeing any windfalls related to stay-at-home and work-from-home behavior.
For AT&T, the big problem is that the value of their purchase of Time Warner has been hurt by the pandemic, and in fact their overall media/content position is in what can only be called “disorder”. AT&T’s wireline base is too distributed for traditional infrastructure to profitably reach it with high-speed Internet. Mobile is their hope, and it seems very possible that everything at AT&T will focus on mobile technology, even what used to be “wireline” delivery.
Verizon has a better position with fixed broadband demand density, but most of their FTTH-suitable territory has already been served. They also need to be thinking about 5G as a means of reaching those customers FiOS can’t profitably serve. Since they’re not (currently) proposing to deemphasize content, they also have to ask what they’ll do for video to these non-FiOS customers—they may need a streaming service.
Moving along, how did the public cloud providers do? Google Cloud had the largest revenue gain for the quarter at 45%. Market-leader Amazon’s AWS sales were up 29% in the last quarter, and Microsoft saw 31% growth in sales. All these are decent numbers, none show any massive shifts in market share (though obviously market-leading Amazon has a bigger barrier to increased sales than up-and-coming players). I do think that both Google and Microsoft are benefitting from hybrid cloud, a cloud computing model Amazon doesn’t have enough premises street creds to support with a compelling story.
The big question among the three is really Google versus Microsoft. Google is doing fairly well with hybrid cloud and enterprises, in no small part because it has a truly foundational vision for the cloud, embodied in things like Kubernetes and Istio. While it doesn’t have the direct account influence of Microsoft (yet), it’s moving well. Google, among the public cloud providers, best represents the leading edge of true cloud-native applications. If there is a cloud-native wave, they may surf it best.
More significantly for the market is the fact that public cloud revenues didn’t explode in the post-COVID planning age. Shifting compute from a capital budget to an expense would be a safe play if a major problem in the economy was expected, so it would seem that enterprise buyers aren’t yet saying that they’ll have to pull in their horns in a serious way. That could mean that IT spending overall won’t be hit as badly in the last quarter and into 2021 as some had feared.
Network equipment hasn’t been much of a bright spot in the recent past, and that still seems true. Cisco beat slightly on earnings and revenues but disappointed on guidance. Juniper beat on revenues and missed on earnings. Nokia’s numbers disappointed, and the company announced some reorganization al moves. Ericsson was the bright spot; they beat estimates and their guidance was reasonable.
Service provider numbers were generally disappointing for the vendors here, but Ericsson clearly has benefitted from the push against Huawei, the habitual price-leader in the mobile market, and from 5G interest. The real story here, at least in the longer term, is likely to be the open-model networking movement.
AT&T has been an aggressive promoter of white-box networking in its 5G mobile space, and also announced its core would now run on DriveNets software and white boxes. Open RAN is creating an explosion of interest and early commitments, and it seems very likely that in early 2021 it may be a major factor in the financial performance of network vendors overall. Because operators have no clear source of improved revenue per bit, they’re putting increased pressure on costs, and the most reliable way to do that is to adopt open-model networks.
On the enterprise side, there’s still hope for the network vendors, but also the prospect of future challenges. Enterprise spending on network technology has already shifted as businesses moved away from building private IP networks to consuming first VPNs and increasingly SD-WAN. Cloud computing is likely to sustain some growth in data center switches and even some access routers. Juniper did better than expected in the enterprise space, in particular.
The challenge for enterprise network spending is really the mirror image of the operator profit-per-bit problem. Enterprises have, for decades, created IT budgets from a combination of “modernization” spending to sustain current applications, and “project” spending where new business cases could justify spending increases. Nearly all of these are based on projected productivity enhancements (some relate to regulatory changes, M&A, and other factors), so in the long run it’s important to identify new ways that enterprises could use IT and networks to make workers more productive.
Juniper’s Mist-AI deal seems particularly promising, and they’ve augmented it with the recent acquisition of 128 Technology, an SD-WAN and virtual-network vendor who offers session-aware traffic handling and statistics and a platform strategy that starts with basic metrics and monitoring and moves upward. The exact nature of the marriage isn’t known yet because the deal hasn’t closed, but it could provide at least a mid-term boost in the enterprise, and also translate into improved managed service platform sales to operators. If they carry it further, 128 Technology’s SD-WAN strategy could become a centerpiece for network-as-a-service thinking, and combined with Mist AI, could give Juniper an enviable position in networking overall.
Moving on, let’s take a look at the IT side of the story. IBM delivered better-than-expected results for the quarter, mostly because of Red Hat and (to a lesser degree) its cloud service and AI. I think it’s clear that IBM is working harder to leverage Red Hat, but that the company isn’t quite there yet, in terms of culture and technology integration. VMware, rival in particular to IBM’s Red Hat, also beat expectations. The two companies are likely to collide directly with their carrier cloud aspirations, but carriers themselves seem lukewarm on making any near-term commitment to the concept, so that collision may not be realized until mid-2021.
I think the big question raised by the IT players is whether public cloud or cloud-platform software will emerge as the framework for future application development. I’ve already noted that Google’s cloud story is the most insightful from a cloud-native perspective. Who among the cloud-platform players can sing as prettily? VMware and IBM are jousting now, and while carrier cloud and 5G may be the early battleground, a stronger, broader, more interesting cloud story will be needed for a clear win.
OK, if we throw all these data points in, like Yarrow Sticks in I Ching, what hexagrams can we read?
First, the US economy has proven more resistant to COVID than its population, perhaps. The likely reason is that the greatest impact of the virus has been on service jobs, and these have less an impact on the consumer economy and B2B in at least the early stages. The impact is likely to grow, however, if the problems extend beyond 2020.
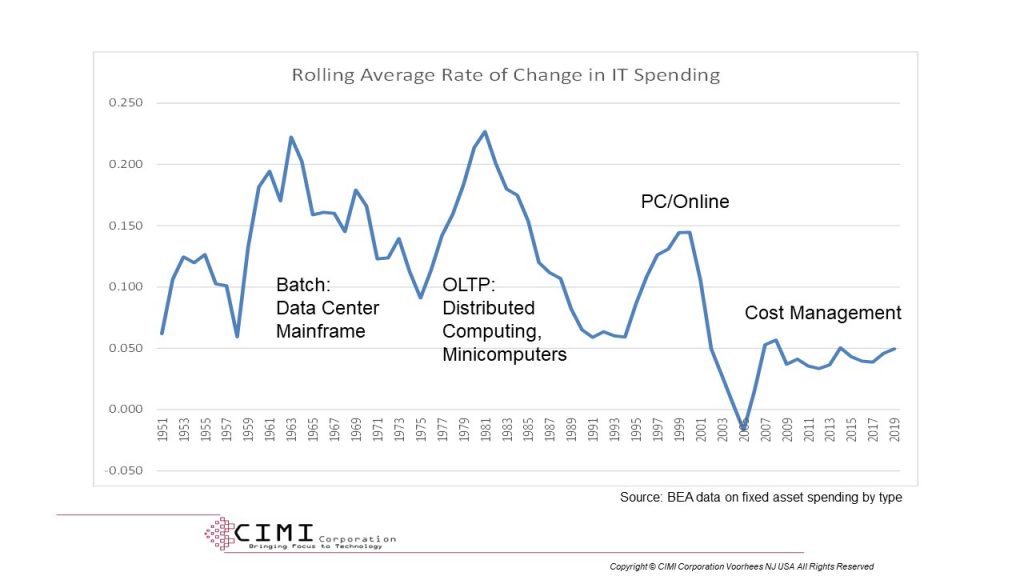
Second, there is a general problem impacting business technology that’s harder to dismiss, and that problem is return on investment—business case, if you prefer. People buy stuff on a whim, and as long as their income holds up, their buying holds up. Businesses need a justification, and across the board, we’re running out of justifications for new spending. The most profound truth of this century has been that we’ve been unable to produce new justifications for business IT and network spending, and that’s driving businesses overall to cost management measures for new projects. “The purpose of this new spending project is to define and implement a model whereby we spend less”; that’s a bit of an oxymoron, and you can see the result.
Third, we’re firmly into a new technology age, one where software is everything and hardware is just something you run software on. That’s been true in computing, and it’s becoming true in networking. The shift to cloud-hosting of network features is, at this point, less important than the substitution of white boxes for proprietary devices. “Disaggregation”, which in one of its flavors means separation of hardware and software, offers the opportunity for buyers to purchase generic devices that can run a variety of software packages. If there’s a standard “platform”, meaning operating system, chip drives, and middleware (including operations and orchestration), then there’s more likely to be standardized software, software interchangeability, and investment protection. None of this is guaranteed, so we need to be thinking more of white-platform than white-box.
Forth, we don’t know where operators really plan to go with regard to transformation. While both public cloud providers and platform software vendors like VMware and IBM are positioning for the opportunities, nothing much is hitting the bottom line yet. Operators may just be laying out postulates rather than making commitments at this point, which suggests that there’s still a lot that could be done to sway their decisions. This is the largest pile of money on the table for the 2021-2023 period, so it’s worth going after.
Finally, we need to escape hype-driven, superficial, technology coverage. I remember a conversation I had years ago with a self-styled industry visionary: “Your trouble is that you’re sailing at fifty thousand feet and your buyers are at sea level,” I said, and it was true. Bulls**t has less inertia than real hardware and software, and less than real people. We have to lead people to literacy on new technologies, and that’s not going to happen with some superficial crap like “How many new ‘Gs” can you postulate in wireless?” Just because it’s easier to write a story that changes a “5” to a “6” than to write one that addresses the real needs of a mobile network evolution/revolution doesn’t mean we have to do that.