Light Reading did a thoughtful piece on NFVi yesterday, and it highlights a number of points we should be thinking about when we talk about “NFV”, “cloud-native”, and “transformation”. Some of the points show we’re at least thinking in the right direction, but others show we still have a long way to go.
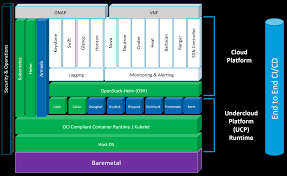
NFVi stands for “NFV Infrastructure”, the term the NFV ISG gave to the collection of hosting and connection resources that are drawn upon to host virtual network functions (VNFs). The presumption in the ISG material is that the link point between management and orchestration (MANO) and NFVi is the Virtual Infrastructure Manager (VIM). From the first, it was assumed that the VIM would be based on OpenStack.
Also from the first, it was clear to at least some people (including me) that the concept of the VIM as the virtualization mid-point to NFVi had issues. If we assume that we have a single VIM representing the totality of NFVi, then we have to make it support whatever we want to deploy, and also need it to make the choices of how to apply resources to services, since the resources are abstracted below the VIM. The problems with this take a moment to explain.
The biggest problem is VIM device support complexity. Suppose you want to host on containers, or bare metal, or in a public cloud service. All of these have different management interfaces, so you’d need to have a plug-in for each. Imagine a typical operator network that might have two or three network vendors, perhaps a dozen different devices, and then add in the hosting. How many hypervisors, container systems, and so forth? The number of permutations of all of this are astounding, and no vendor would supply a VIM that supported competitive equipment, so it’s an integration problem.
The next problem is that if there one VIM that represents all NFVi, then any decisions you make on where to host, what technology to use, and so forth, have to be pushed down into the VIM itself. MANO service modeling (if indeed there is any such thing) is reduced to simply saying “host” and letting something else figure out everything else. The VIM then has to become a second-level orchestrator, and its details in that role are not even discussed in the ISG work.
There are two possible ways of addressing this. One is to have multiple VIMs, one for each resource domain. The higher-level model then picks a VIM when it makes a hosting decision, implicitly, because it picked a place to host. There is still a need for that invisible sub-orchestration within the resource domain. The second possibility is to define a set of “service-layer” models and a set of “resource-layer models” that define the respective orchestration tasks, and view the VIM as representing the boundary where service-layer and resource-layer mapping happens. I tried out both approaches and like the second one best; see my ExperiaSphere tutorials.
The problems cited in the article are due in part to the fact that the NFV ISG didn’t really pick either of the choices, which tends to create a very brittle coupling between the VNFs that you want to deploy and the resources you want to deploy them on. The VIM of today doesn’t really abstract the NFVi, and that’s what makes VNF-to-NFVi connections almost specialized.
The other part, an issue we’re really not fully confronting even now, is the problem of automating the service lifecycle. In order to do that, you have to define a goal-state “intent model” for the pieces of a service, and map the result to abstract resources. Without this, you have no easy way to figure out what you’re supposed to do with a service event. I know I sound like a broken record on this, but this problem was solved using data-model-coupled event-to-process mapping when the TMF published its original NGOSS Contract stuff a decade ago. Why we (and even the TMF) forgot that, I can’t speculate.
My point here is that in a theoretical sense, there is no such thing as an NFVi that’s “too fragmented”. Infrastructure reality is what it is, and the whole purpose of virtualization or abstraction is to accommodate the diversity of possibilities. If you don’t have that, the fault lies in what’s supposed to be doing the abstracting, which is the VIM. The VIM concept, candidly, frustrates me because I’ve spoken against the monolithic VIM vision from the first and even demonstrated to operators that it wouldn’t work. That the point wasn’t understood back almost six years ago speaks to the problem of a lack of software architecture skill in the standards process.
How about a practical sense? The article notes that one problem is that VNFs themselves demand different NFVi configurations, because of specialization in the hosting requirements. The recommendation is to define only three classes of hosting for VNFs so that you limit the fragmentation of the resource pool created by the different VNF configuration requirements. Is this a real issue?
Only maybe. First, we’re at risk diving into the hypothetical when we talk about this topic. Do the differences in configuration really create significant benefits to VNF performance? How many VNFs of each of these three types would be hosted? How different are the costs of the configuration for each, and would those cost differences be partially or fully offset by improved resource efficiency? Do we reach a level of resources for each of the three configurations that we’ve achieved optimal efficiency anyway? All this depends on what we end up deploying as VNFs.
Which we don’t know, and in one sense we shouldn’t be writing the concerns about this into specifications on the architecture. The architecture should never constrain how many different resource classes we might want, which parameters might be selected to decide where to hist something. I think that the simple truth is that operators should have a MANO/VIM/NFVi model that accommodates whatever they want to run, and what they want to run it on. Let the decision on what specific resources to deploy be made by how resource consumption develops.
What really frightens me, though, is that the GSMA is looking into framing out some “NFVi categories”. It frightens me because it implies we’re going to take an architectural vision that had major issues from the start, and that has since been diverging from the cloud’s vision, and use it as a basis for framing categories of resources to be used in the carrier cloud. You don’t do the right thing by building on a vision that’s wrong.
What all virtualization needs, even depends on, is a true and dualistic vision. In the “upward” direction, it has to present a generalized and comprehensive view of the virtual element or resource, one that envelops all the possible realizations of that element, whether they’re a singular resource or a collection acting cooperatively. In the “downward” direction, it has to realize that upward vision on any suitable platform or pool. That means that “NFVi” shouldn’t be the focus of virtualization for NFV, that the VIM has been the critical piece all along. The sooner we deal with that, the better.