DriveNets has long supported a containerized-software framework that’s hosted in a disaggregated cluster of white-box elements. In effect, it’s a little cloud of its own, and the company even calls it the “Network Cloud”. They also support control-plane separation, and I’ve noted several times that their architecture could be used to bind the IP control plane directly to things like CDN, 5G, and even IoT. In short, I believe the Network Cloud concept has a lot of potential, if the company moves to harness it. Now, they may be just starting to do that.
It’s not that DriveNets hasn’t said their architecture would support third-party elements; they have. They’ve just been a bit coy about it, talking about the capability in a general sense. They’ve gone further than that in a white paper they released recently, titled “NCNF: From ‘Network on a Cloud’ to ‘Network Cloud’: The Evolution of Network Virtualization”. You can download the paper HERE (registration required). What they’re getting at is that the notion of function hosting has, for operators, evolved from being VM-specific (the original NFV model of Virtual Network Functions” to being more cloud-efficient through the use of containers. The end-game? Host the containers in DriveNets’ Network Cloud.
There certainly are a number of problems with the notion that NFV and its VNFs can be made cloud-native simply by running them in containers, and I’ve said all along that the notion of “cloud-native network functions” as the successor to VNFs should be named “containerized network functions” instead, because there is no way that the initiative is going to create truly cloud-native elements, whatever you call them. There’s too much baggage associated with NFV’s management and orchestration approach, and the NFV ISG’s CNF efforts don’t address three big questions about the use of containers or VMs in hosting service functions/features.
Big Qustion One is whether containers alone really provide the benefits of cloud-native behavior. An application isn’t stateless because you run it in a container, it’s stateless because it was written to be, and it will have that property however it’s hosted. As far as state goes, containers fall into a kind of gray zone between stateless and stateful. On the one hand, a container is supposed to be redeployable, which is a property sought in stateless design. On the other hand, containers don’t enforce that, they only pretend the attribute it there. In most business applications, that’s good enough because the containerized applications can recover from a failure and redeployment. In event-based applications like almost everything in networking, it’s not nearly enough.
Big Question Two is whether containers’ model fits virtual functions at all. A lot of the container-versus-VM discussion has centered on the number of each that a server could support (containers win because the OS isn’t duplicated for each, where each VM looks like bare metal). More attention should be paid to the fact that a container system is all about resolving configuration variability and dependencies in the software organization stage, rather than manually (or with DevOps tools) at deployment time. Containers work by setting limitations on how wild and free software can behave. Can NFV’s software be tamed like that? Remember that VNFs require extensive onboarding specialization just to run, much less progress cleanly through a lifecycle.
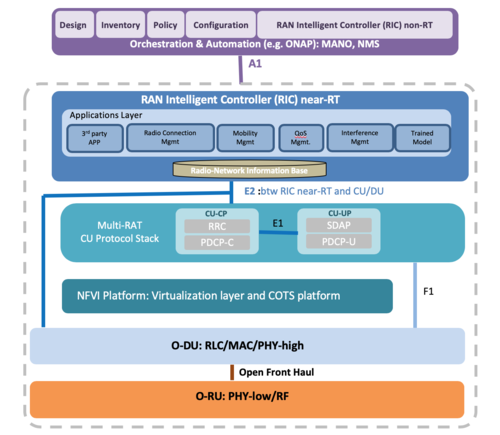
Our last Big Question is whether containers, or any cloud hosting strategy, can meet the latency requirements of many of the applications that are based on hosted functions. The O-RAN, for example, has both a near-real-time and non-real-time RAN Intelligent Controller, whose descriptions make them sound like they include some form of orchestration, something container systems use for deployment and redeployment. Spread latency-sensitive stuff around the cloud in an arbitrary way, and delay accumulation is inevitable.
So how does DriveNets address these Big Questions? We’ll have to make a few presumptions to answer that because of the level of detail in the paper, but here goes.
First of all, DriveNets’ model is a cluster-cloud, designed to deploy service features within itself, where latency is low and where there’s a mixture of general compute and network processor assets available. While this doesn’t offer the broad resource pool that cloud computing is known for, as Question Three noted, the big pool could be wasted on applications where latency issues dictate that things be deployed close to each other. DriveNets clearly addresses Question Three.
The next point is that DriveNets uses a container model, but not standard container orchestration, and it appears that the constraints that DriveNets’ orchestrator (DNOS) imposes on applications keeps them behaving in a more orderly cloud-native-compatible way. However, we have to recognize that standard, badly behaved VNF/CNFs would either behave equally badly with DriveNets or wouldn’t run. This isn’t a criticism of their approach; you can’t really convert physical network functions, the code that’s inside a network appliance, into an optimum cloud-native implementation without recoding it. It’s just that we can’t say that DriveNets fixes the problem of CNFs; it offers another model that would prevent those problems if the model were followed, but we don’t have the details of the model, so we can’t judge whether developing to it would be practical. We can’t give DriveNets a pass on either Question One or Two.
To me, though, those questions aren’t as important to DriveNets’ aspirations as another question, one not related to the whole PNF/VNF/CNF evolutionary dustup. That question is the benefit of having a third-party “NCNF” resident inside the Network Cloud to start with. The right answer to that question could totally validate the NCNF approach, but again, we can’t firmly answer it from the material.
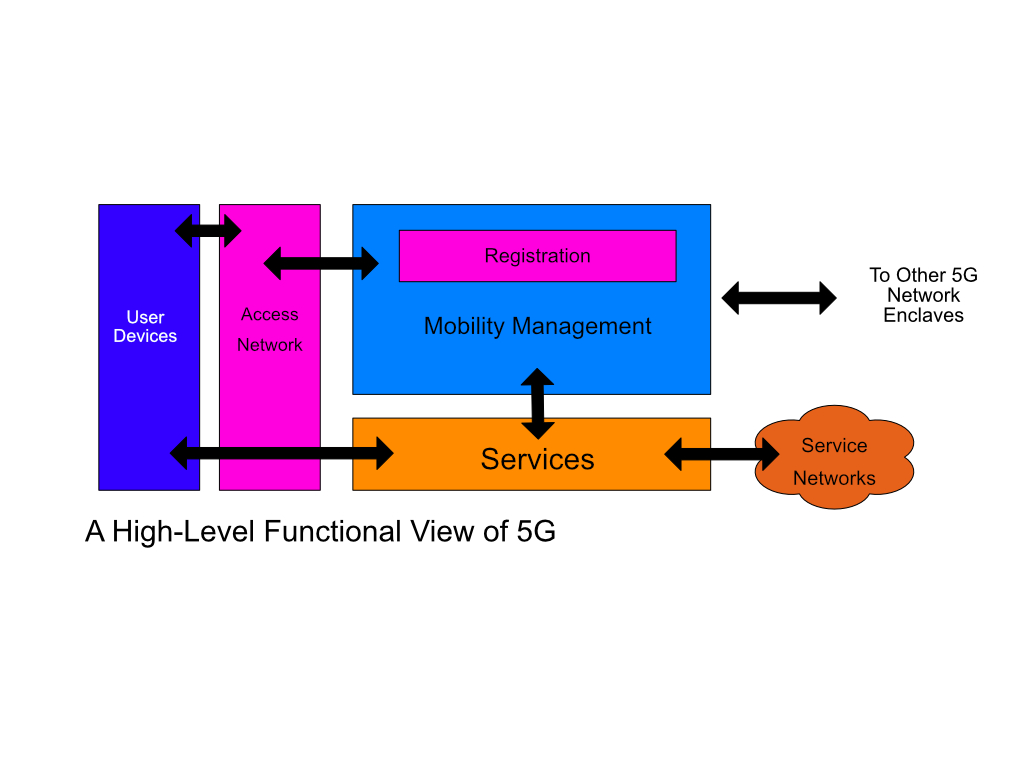
There are two things that you could do with a NCNF application that would be less efficient or even impossible without it. First, you could build a network feature that drew on control-plane knowledge and behavior. You’ve got topology information, state information, a lot of stuff that might be very valuable, and if you could exploit that, you could almost certainly implement higher-layer connection-service-related features better. 5G is a good example. The 5G User Plane is actually the IP control/data plane, so the 5G Control Plane is a higher-layer service feature set. In theory, DriveNets could support this model and provide better services in that layer I’ve called the “service plane” above the IP control plane.
The second thing you could do is also perhaps related or could be related to 5G. You could build a forwarding plane behavior based on something other than adaptive IP. In short, you could create a parallel control plane to the IP control plane, and since you can partition a DriveNets Network Cloud into multiple “forwarding domains” with their own unique rules, the Network Cloud could play a different forwarding tune completely. Inside 5G Core (5G’s equivalent of Evolved Packet Core or EPC), you have to direct tunnels to get user data to the right cells. You could do that directly, without tunnels, using a different forwarding domain within a Network Cloud.
This validate-the-Network-Cloud isn’t just an academic exercise, either. The stronger a point you make about the value of cluster routing as a hosting point for network functions, the more you raise the profile of a competitive concept, edge computing. If clusters are better primarily because the resources are close and the latency low, then server resources similarly clustered together would be good too. If OpenFlow forwarding switches combined with edge-hosted control-plane stuff, you’d end up with something that would answer Question One the same as DriveNets did.
The critical question for is how they would enable the two possible benefits of close control-plane coupling, and the paper doesn’t address that. What I’d like to see from DriveNets is that next level of detail; how NCNF would work, how it would be exploited, and how they’ll control the security and behavioral compliance of any of these parallel domains. The current document adds a bit of diagrammatic meat to the bones of prior statements on third-party feature hosting, perhaps making some of the potential a bit more obvious. It still doesn’t do enough to convey what I think would be the real value of DriveNets’ model, and we need some more detail:
- A description of how DNOR orchestration would control the deployment of third-party elements, perhaps relating it to Docker or Kubernetes.
- A description, even at a high level, of the APIs available to link third-party elements to DriveNets’ operating system and middleware elements (DNOS/DNOR, presumably) and what they’d be used for.
- A description of how higher-level elements could interact with the separate IP control-plane elements of the Network Cloud.
- A description of how third-party elements could create another forwarding instance that would share the Network Cloud infrastructure, and what specific things that software would have to do to interact with the rest of DriveNets’ software.
Maybe the next paper will cover that, DriveNets?