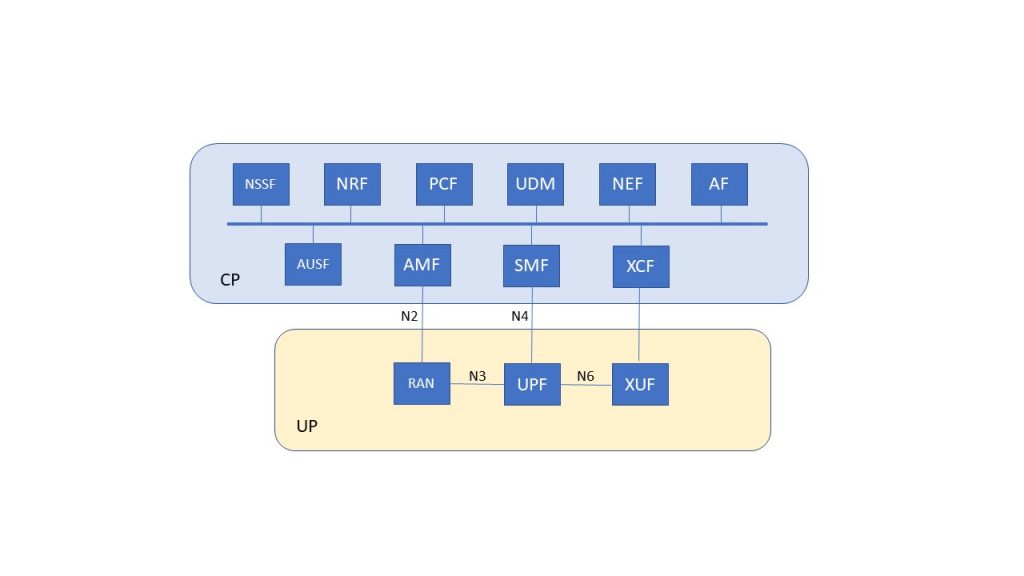
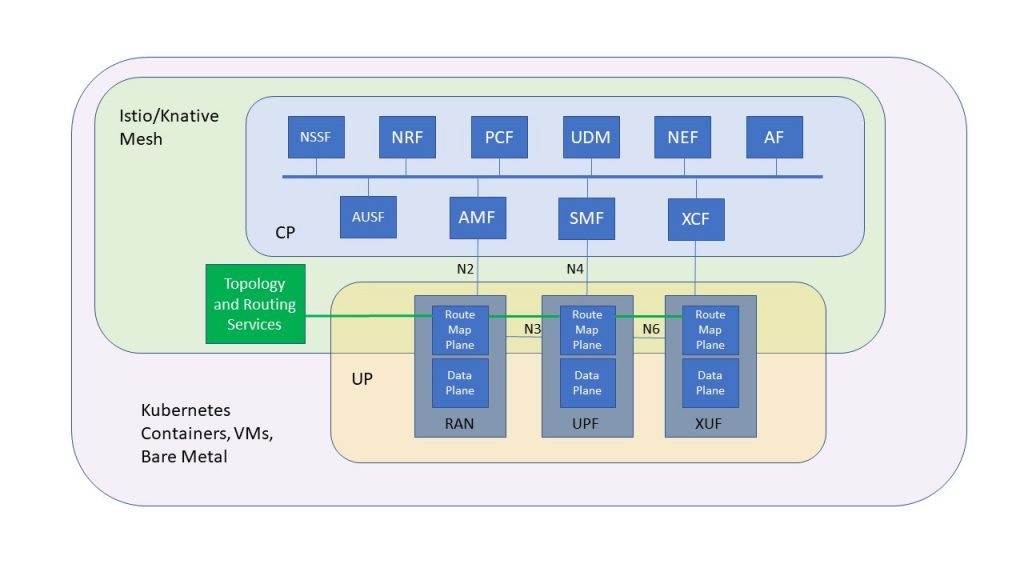
The announcement of ONAP’s Frankfurt Release last month raised a lot of questions from my contacts and clients. There is no question that the release improves ONAP overall, but it still doesn’t change the underlying architecture of the platform. I’ve described ONAP as a “monolithic” model of zero-touch operations automation, and said that model is simply not the right approach. In a discussion with an EU operator, I got some insights into how to explain the difference between ONAP and the (far superior, in my view) TMF NGOSS Contract model.
We think of networks as vast interconnected collections of devices, which is true at the physical level. At the operations level, though, a network is a vast, swirling, cloud of events. An event is an asynchronous signal of a condition or condition change, most often a change that represents a significant shift in state/status. In a pure manual operations world, human operators in a network operations center (NOC) would respond to these events by making changes in the configuration or parameterization of the devices in the network.
An automated lifecycle management system, like those humans in the NOC, have to deal with events, and as usual there’s more than one way to do that. The obvious solution is to create what could be called an “automated NOC”, a place where events are collected as always, and where some automated processes then do what the human operators would do. I’ll call this the “AutoNOC” approach.
The problem with AutoNOC is that by inheriting the human/NOC model, it inherited most of the problems that model created. Two examples will illustrate the overall issue set.
Example One: A major trunk fails. This creates an interruption of connectivity that impacts many different services, users, and devices. All the higher-layer elements that depend on the trunk will generate events to signal the problem, and these events will flood the NOC to the point where there’s a good chance that the staff, or the AutoNOC process, will simply be swamped.
Example Two: An outside condition like a brownout or power failure occurs as the result of a storm, and there are intermittent failures, over a wide area as a result. The events signaling the first of these problems are being processed when events signaling later failures occur, and the recovery processes initiated then collide with each other.
What we really need to fix this problem is to rethink our notion of AutoNOC operation. The problem is that we have a central resource set that has to see and handle all our stuff. Wouldn’t it be nice if we had a bunch of eager-beaver ops types spread about, and when a problem occurred, one could be committed to solve the problem? Each of our ops types would have a communicator to synchronize their efforts, and to ensure that we didn’t have a collision of recovery steps. That, as it happens, is the TMF NGOSS Contract approach.
The insight that the NGOSS Contract brought to the table was how to deploy and coordinate all those “virtual ops” beavers we discussed. With this approach, every event was associated with the service contract (hence the name “Next-Generation OSS Contract”), and in the service contract there would be an element associated with the particular thing that generated the event. The association would consist of a list of events, states, and processes. When an event comes along, the NGOSS Contract identifies the operations process to run, based on the event and state. That process, presumed to be stateless and operating only on the contract data, can be spun up anywhere. It’s a microservice (though that concept didn’t really exist when the idea was first advanced).
The beauty of this should be obvious. First, everything is infinitely scalable and resilient, since any instance of a state/event process can handle the event. If you have two events of the same type, you could spin up two process instances. However, if the processing of an event launches steps that change the state of the network, you could have the first event change the state so that a second event of the same kind would be handled differently. The data model synchronizes all our ops beavers, and the state/event distribution lets us spin up beavers as needed.
What do these processes do? Anything. The obvious thing is that they handle the specific event in a way appropriate to the current state of the element. That could involve sending commands to network elements, sending alerts to higher levels, or both. In either case, the commands/alerts could be seen as events of their own. The model structure defines the place where repair is local, where it’s global, and where it’s not possible and some form of higher-layer intervention is required.
I’ve blogged extensively on service models, and my ExperiaSphere project has a bunch of tutorials on how they work, in detail, so I won’t repeat that piece here. Suffice it to say that if you define a proper service model and a proper state/event structure, you can create a completely cloud-native, completely elastic, completely composable framework for service automation.
Now contract this with AutoNOC. Classic implementation of this approach would mean that we had an event queue that received events from the wide world and then pushed them through a serial process to handle them. The immediate problem with this is that the process isn’t scalable, so a bunch of events are likely to pile up in the queue, which creates two problems, the obvious one of delay in handling, and a less obvious one in event correlation.
What happens if you’re processing Item X on the queue, building up a new topology to respond to some failure, and Item X+1 happens to reflect a failure in the thing that you’re now planning to use? Or it reflects that the impacted element has restored its operation? The point is that events delayed are events whose context is potentially lost, which means that if you are doing something stateful in processing an event, you may have to look ahead in the queue to see if there’s another event impacting what you’re trying to do. That way, obviously, is madness in terms of processing.
My view is that ONAP is an AutoNOC process. Yes, they are providing integration points to new services, features, and issues, but if the NGOSS Contract model was used, all that would be needed is a few new microservices to process the new state/events, or perhaps a “talker” that generates a signal to an OSS/BSS process at the appropriate point in service event processing. Even customization of a tool for service lifecycle automation would be easier.
My concern here is simple. Is ONAP, trying to advance further along functionally, simply digging a deeper hole? The wrong architecture is the wrong architecture. If you don’t fix that problem immediately (and they had it from the first) then you risk throwing away all enhancement work, because the bigger a monolith gets, the uglier its behavior becomes. Somebody needs to do this right.