How would a separate control plane for IP work? What would it facilitate? It’s pretty obvious that if you were to separate the control and data planes of IP, you could tune the implementation of each of these independently, creating the basis for a disaggregated model of routing versus the traditional node-centric IP approach, but why bother? To answer these questions, we have to go back in time to early attempts to work non-IP “core networks” into an IP network.
The classic, and most-technology-agnostic, view of a separate control plane is shown in the figure below. In it, and in all the other figures in this blog, the blue arrows represent data-plane traffic and the red ones the control-plane traffic. As the figure shows, the control plane sets the forwarding rules that govern data-plane movement. Control-plane traffic (at least that traffic that’s related to forwarding control or state) is extracted at the entry interface and passed to the control plane processing element. At the exit interface, control-plane traffic is synthesized from the data the processing element retains.
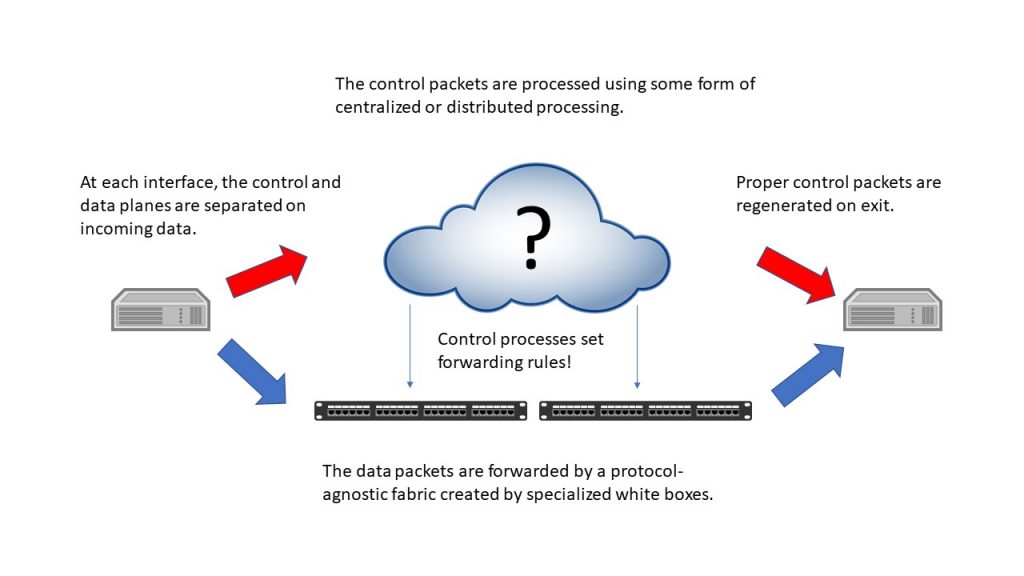
The earliest example of something like this is decades old. Back in the 1990s, when ATM and frame relay were just coming out, there was interest in utilizing widespread deployment of one or both of these networks for use with IP. Either protocol created “virtual circuits” analogous to voice calls, and so the question was how to relate the destination of an IP packet that had to travel across one of these networks (called “Non-Broadcast Multi-Access” networks) with the IP exit point associated with the destination. The result was the Next-Hop Resolution Protocol, or NHRP.
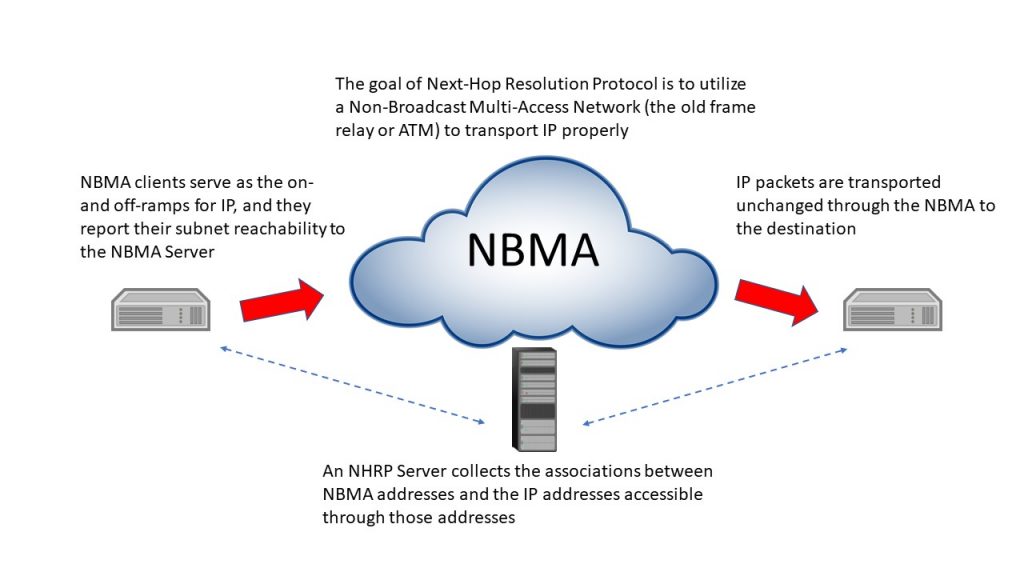
NHRP, shown in the figure above, visualizes NHRP operation. The IP users are expected to be in “Local Independent Subnets” or LISs, and a LIS is a Level 2 enclave, meaning it doesn’t contain routers. The gateway router for the LIS is an NHRP client, and each client registers its subnet with the NHRP server. When the NHRP client receives a packet for another LIS, it interrogates the server for the NBMA address of the NHRP client that serves the destination. The originating Client then establishes a virtual connection with the destination Client, and the packets are passed. Eventually, if not used, the connection will time out.
NHRP never had much use because frame relay and ATM failed to gain broad deployment, so things went quiet for a while. When Software-Defined Networking was introduced, with the ONF as its champion, it proposed a different model of non-IP network than ATM or frame relay had proposed, and so it required a different strategy.
The goal of SDN was to separate the IP control plane from forwarding to facilitate centralized, effective, traffic engineering. This was done by dividing IP packet handling into a forwarding-plane element and a control-plane element. The forwarding plane was expected to be implemented by commodity white-box switches equipped with the OpenFlow protocol, and the control plane was to be implemented using a central SDN controller.
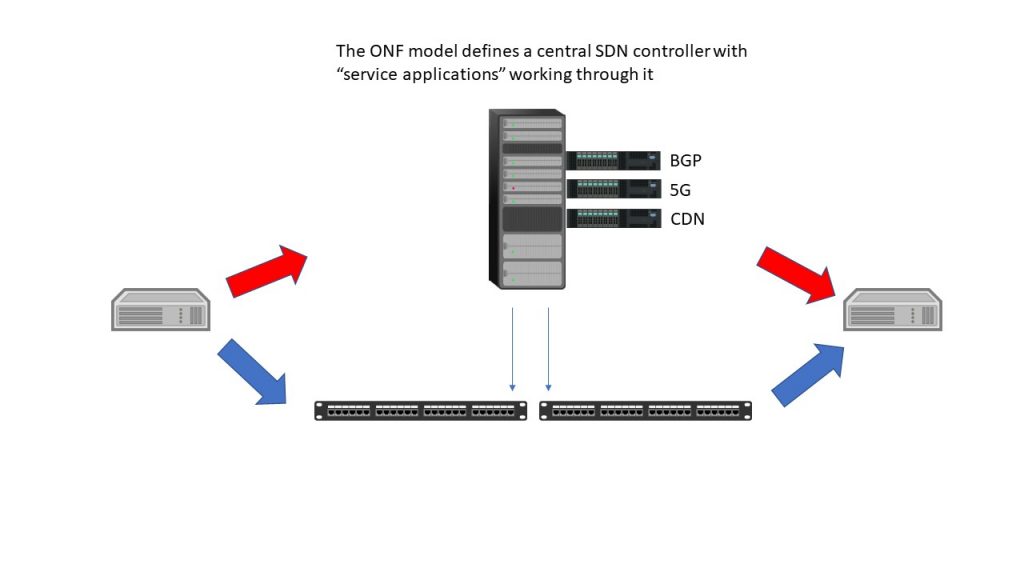
In operation, SDN would create a series of protocol-independent tunnels within the SDN domain. At the boundary, control packets that related in any way to status or topology would be handled by the SDN controller, and all other packets would be passed onto an SDN tunnel based on a forwarding table that was maintained via OpenFlow from the SDN controller.
While the principle goal of SDN was traffic engineering, it was quickly recognized that if the SDN controller provided “northbound APIs” that allowed for external application control of the global forwarding table and the individual tables of the forwarding switches, the result would allow for application control of forwarding. This is the current SDN concept, the one that was presented in the recent SDN presentation by the ONF, referenced in one of my earlier blogs.
This SDN model introduced the value of programmability to the ONF approach. Things like the IP protocols (notably BGP, the protocol used to link autonomous systems, or ASs, in IP) and even the 5G N2/N4 interfaces, could now be mapped directly to forwarding rules. However, the external applications that controlled forwarding were still external, and the IP control plane was still living inside that SDN controller.
The fact that Lumina Networks closed its doors even as it had engagements with some telcos should be a strong indicator that the “SDN controller” approach has issues that making it more programmable won’t resolve. In fact, I think the biggest lesson to be learned from Lumina is that the monolithic controller isn’t a suitable framework. How, then, do we achieve programmability?
Google had (and has) its own take on SDN, one that involves both traffic engineering and a form of network function virtualization. Called “Andromeda”, the Google model was designed to create what’s turned out to be two Google backbone networks, one (B2) carrying Internet-facing traffic and the other (B4) carrying the inter-data-center traffic involved in building experiences. Andromeda in its current form (2.2) is really a combination of SDN and what could be described as a service mesh. Both the IP control plane and any of what were those “external applications” in SDN are now “microfeatures” implemented as microservices and hosed on a fabric controlled by SDN and OpenFlow. The latency of the fabric is very low, and it’s used both to connect processes and to pass IP protocol streams (the two data sources for those two Google backbones).
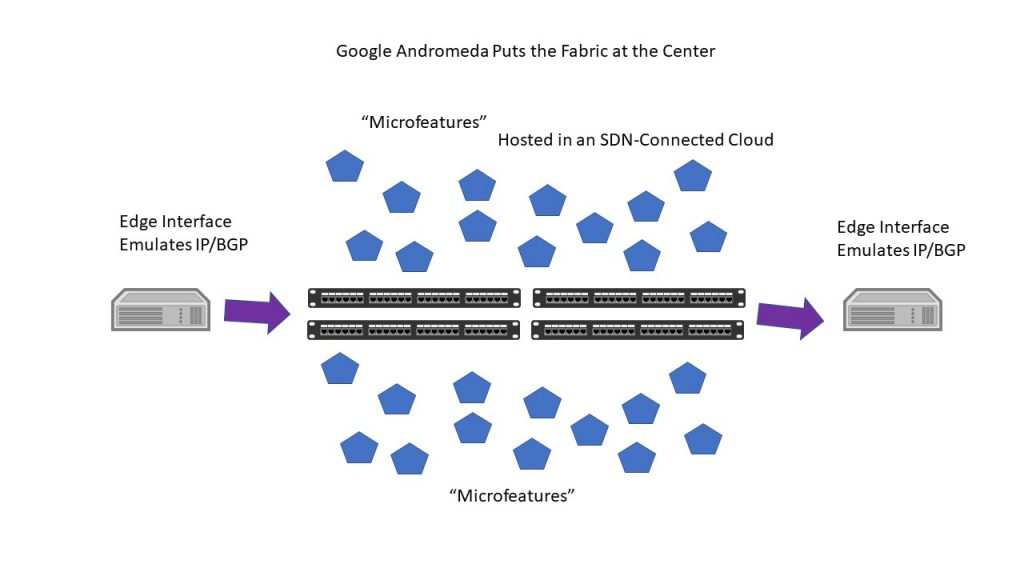
With Andromeda, virtual networks are built on top of an SDN “fabric”, and each of these networks is independent. The early examples of Andromeda show them being based on the “private” IP address spaces, in fact. Networks are built from the rack upward, with the basic unit of both networking and compute being a data center. Some of Google’s virtual networks extend across multiple locations, even throughout the world.
Andromeda could make a rightful claim to being the first and only true cloud-native implementation of virtual functions. The reliance on microfeatures (implemented as cloud-native microservices) means that the control plane is extensible not only to new types of IP interactions (new protocols for topology/status, for example) but also “vertically” to envelope the range of external applications that might be added to IP.
An example of this flexibility can be found in support for 5G. The N2/N4 interfaces of 5G pass between the control plane (of 5G) and the “user plane”, which is IP. It would be possible to implement these interfaces as internal microservice APIs or events, coupled through the fabric between microfeatures. It would also be possible to have 5G N2/N4 directly influence forwarding table entries, or draw on data contained in those tables. For mobility management, could this mean that an SDN conduit created by OpenFlow could replace a traditional tunnel? It would seem so.
It’s worthwhile to stop here a moment to contrast the ONF/SDN approach and the Google Andromeda approach. It seems to hinge on two points—the people and the perceived mission. The ONF SDN model was created by network people, for the purposes of building a network to connect users. The Google Andromeda approach was created by cloud people to build and connect experiences. In short, Google was building a network for the real mission of the Internet, experience delivery, while the ONF was still building a connection network.
I think the combination of the ONF concept and the Google Andromeda concept illustrates the evolution of networking. If operators are confined to providing connectivity, they’re disconnected from new revenue sources. As a cloud provider, an experience-centric company, Google designed a network model that fit the cloud. In point of fact, they built the network around the cloud.
I’ve blogged about Andromeda dozens of times, because it’s always seemed to me to be the leading edge of network-think. It still is, and so I think that new-model and open-model networking is going to have to converge in architecture to an Andromeda model. Andromeda’s big contribution is that by isolating the data plane and converting it to simple forwarding, it allows cloud-hosted forwarding control in any form to be added above. Since networks and network protocols are differentiated not by their data plane but by their forwarding control, it makes networks as agile as they can be, as agile as the cloud.
Where “above” turns out to be is a question that combines the issues of separating the control plane and the issues of “locality” (refer to my blog HERE). I think the Andromeda model, which is only one of the initiatives Google has undertaken to improve “experience latency” in the cloud, demonstrates that there really should be cooperation between the network and any “service mesh” or microfeature cloud, to secure reasonable accumulative latency. To make that happen, the process of placing features, or calling on feature-as-a-service, has to consider the overall latency issues, including issues relating to network delay or feature deployment.
There’s also the question of what specific microfeatures would be offered in the supercontrol-plane model. Obviously, you need to have a central topology map for the scope of the supercontrol-plane and obviously you have to be able to extract control-plane packets from the interface and route them to the supercontrol-plane, then return synthesized packets to the exit interfaces. How should all this be done, meaning how “microfeatured” should we go? There’s a lot of room for differentiation here, in part because this is where most of the real service revenue potential of the new model would be created. Could an entire CDN, for example, be migrated into the supercontrol-plane, or an entire 5G control plane layer?
A supercontrol-plane strategy that would allow new-model networking to be linked to both revenues in general and 5G in particular would be a powerful driver for the new model and white boxes. By linking white boxes to both the largest source of greenfield deployment (5G) and the strongest overall driver for modernization (new revenue), supercontrol-plane technology could be the most significant driver for change in the whole of networking, and thus the greatest source of competition and opportunity. Once vendors figure this out, there will likely be a land-rush positioning effort…to some variant on one of the approaches I’ve outlined. Which? Who knows?
While all of this clearly complicates the question of what the new network model might be, the fact is that it’s still a good sign. These issues were never unimportant, only unrecognized. We’re now seeing the market frame out choices, and in doing that they’re defining what differentiates the choices from each other. Differentiation is the combination of difference and value, and that’s a good combination to lead us into a new network age.