Could we have built NFV around containers? Could we still do that? That, in my view, is the most important question that NFV proponents should be asking. We have a lot going on with NFV, but movement (as I’ve said before) is very different from progress. If there’s a right way to do NFV, we should be assessing that way and promoting the things that are needed to adopt it. If we’re doing things that don’t promote the right way, we’re worse than spinning our wheels, because we’re distracting the industry from the best course.
If you launch an architecture aimed at replacing purpose-built network devices with cloud-hosted technology (which is what NFV did), the logical place to start your thinking is the nature of that cloud-hosted technology. What would the ideal hosting framework look like? The best place to start is with the obvious visible properties that contribute to the business case.
NFV hosting has to be pervasive, meaning that we have to be able to define a lot of connected hosting points and allocate capacity to virtual network functions (VNFs) based on the specific needs of the VNF and the overall topology of service traffic. We can’t make NFV work if the only hosting resource we have is a hyperconverged data center in some central location, like St. Louis in the US.
We also have to make NFV hosting highly efficient and agile. The business case for NFV depends on being able to operate a hosted-function-based service for less than we’d spend on a service created by purpose-built devices. We already know, and so do the operators, that capex savings alone will not justify NFV.
NFV infrastructure has to protect service tenants from misbehavior. This is a bit of a delicate question, because the extent to which VNFs can misbehave depends on the rigor with which operators qualify them for deployment, and whether operators would allow service users to deploy their own. Since we can’t answer for all future needs, we have to assume that we can tune the level of tenant isolation in NFV to suit current requirements.
These three baseline requirements point to a virtualization-based hosting ecosystem. In my last couple of blogs, I’ve suggested that a key requirement for such an ecosystem is a universal, ecosystem-wide, model for deployment and redeployment. We have to be able to deploy a function where we decide we need it to be, without having to vary our procedures according to where we put it. We also need to be able to lifecycle-manage it in that spot, again using consistent processes. This to me means that what NFV calls “NFVI” should be a pool of resources overlaid with a uniform virtualization software foundation.
The NFV ISG has kind of accepted this approach by saying that virtual machines and OpenStack are at least accepted if not preferred models for NFVI. Is that best, though? At the time (2013) when NFV gained structure, VMs were the best thing available. Now, containers in general, and the DC/OS-and-Mesos model of container deployment in particular, are better.
Containers are more efficient in hosting small units of functionality because they don’t demand that every such unit have its own independent operating system, which VMs do. This could be a critical benefit because you can host more VNFs on a given platform via containers than via VMs. It’s particularly important if you follow the implicit model that the NFV ISG calls “service chaining”, where multiple serially connected functions hosted independently (and on different platforms) are connected as “virtual CPE”.
The problem with containers is that they don’t provide the same level of tenant isolation as virtual machines do. Different VMs on the same host are almost ships in the night, sharing almost nothing except an explicitly bounded slice of the physical server. Containers share the OS, and while OS partitioning is supposed to keep them separate, it is possible that someone might hack across a boundary.
The DC/OS solution to this is to allow a container system to run on VMs. In fact, this capability is implicitly supported in containers (a container system could always run in any VM, even in the cloud), but operationalizing this sort of framework demands some special features, which the DC/OS software provides. The features also support scaling to tens of thousands of nodes, which is part of our requirement for pervasive deployment. Every node, data center, collection, or whatever you want to call it, is supported in the same way under DC/OS because it runs the same stuff.
One of the issues that I don’t think the NFV ISG ever really faced is that of managing the address space for NFV. You cannot, consistent with security/isolation requirements, let all of the pieces of an NFV service sit grandly visible on the data plane of the service network. My company VPN should not contain the addresses of my VNFs, period. However, I have to address VNFs or I can’t connect them, so what address space do they use?
In container networking, this issue isn’t addressed consistently. Docker basics don’t do much more than say that an application deploys within a private subnet as the default, though you can also deploy onto the “host” or customer/service address space, public IP addresses. We need two things here. First, we need to decide what address spaces really exist, and second, we need to decide how we’re going to network within and among them.
The logical model for VNF deployment says that each service (consisting, in principle, of multiple VNFs) lives in a private IP address space, and all the VNFs in the service have addresses in that space. The classic home-network 196.168.1.x address space offers up to 255 addresses, but there are 256 Class A addresses available to use, so the space has 65 thousand plus addresses. There are also 16 Class B spaces that have 4096 addresses per Class B, for over a million available addresses, and a single Class A that has almost 17 million available addresses. The smart strategy would be to use Class A or B addresses to deploy “services” whose elements needed to be interconnected within a virtual device or intent model (meaning, connected so they’re invisible from the outside). You would then translate the addresses of interfaces that had to be visible in the service address space to the user’s addresses, and those that had to be visible to operations to an operations space. The latter space would be a Class A, probably.
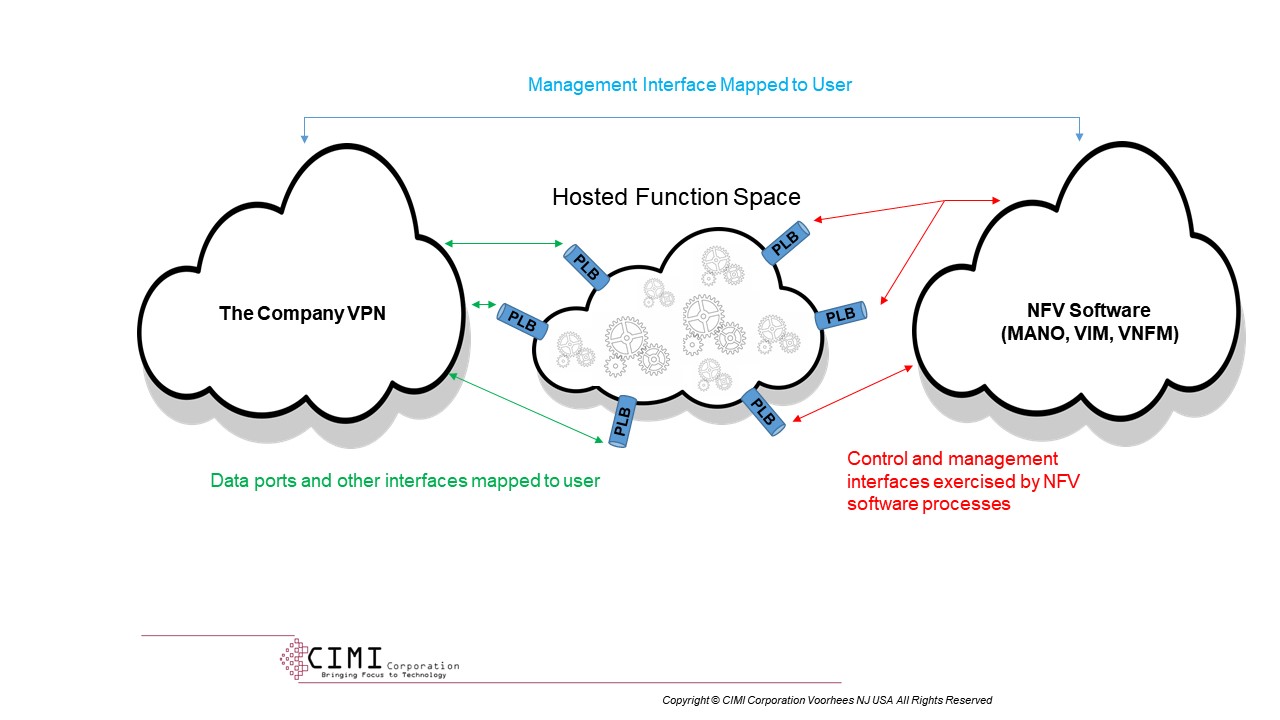
When we deploy an NFV service, then, we’d be hosting the connected VNFs within a private address space, which you remember means that the addresses can be reused among services, since they don’t see the light of day. Each such service would have a set of interfaces exposed to the “data plane” or service addresses, like the company VPN, and each would have a set of interfaces exposed to the control/operations plane of the NFV infrastructure and management framework, probably that private Class A. If there’s a user management port that’s reflected from NFV VNFM, it would be translated into the user address space from the NFV address space. If we refer to THIS FIGURE, some of the “Proxy Load Balancers” (PLBs) exposed by the NFV software from the private address space would go to the service data plane’s address space and some to the NFV/VNFM address space.
{kind=link}
The “how” in addressing and networking that DC/OS defaults to is the overlay VPN model, which in this case is the Navstar plugin, but you could substitute other models like Juniper’s Contrail and (my favorite) Nokia/Nuage. The nice thing about this approach is that it reduces the overhead issues that other container networking can add, which improves throughput, as well as managing addressing fully.
Some applications in NFV may either require VMs for security/performance reasons, or have a nature that doesn’t particularly match container benefits. A good example of the “poor fit” problem is the hosting of the mobile-network features in IMS, MMS, and EPC. With DC/OS you have the option of deploying on VMs “under” containers, and if you use a good SDN networking tool you can integrate container and VM deployments.
What would this do for NFV? One thing I think is clear is that a framework like containers and DC/OS lets you visualize deployment and connectivity details explicitly rather than letting you go abstractly about notions of function hosting and management without any clear deployment model in mind. For example, if we know that VNFs are hosted in containers, then we know what we need operationally to deploy and connect them. When’s the last time you heard of a container application driven by an ETSI descriptor like a VNFD? Instead of describing abstract stuff, we could have identified just what container deployment features were needed and what specific capabilities they had to provide. Anything missing could be taken back to the open-source project that launched the container system (DC/OS in my example). What wasn’t missing could be described and standardized with respect to use.
What’s more, this approach largely eliminates the “interoperability” issues of NFV. Yes, there are still some practices that need to be harmonized, like how the NFV software exposes management interfaces for services or how local application ports for management (CLI or even Port 80 web interfaces) are used, but the issues are exposed as soon as you map to the presumed container structure, and so you can fix them.
Best of all? This works. Mesos and DC/OS have been proven in enormous deployments. The technology comes from social networking, where scale of service and resources is already enormous. We’re not inventing new hosting, new orchestration, new management. There are no large-scale NFV-architected deployments today.
Could this be made to work for NFV? Almost certainly ONAP could be adapted to deploy in this framework, and to deploy VNFs there too. The question is whether the current course could be diverted toward a container-based model, given that there is a questionable business case for large-scale NFV deployment in any event. I’ve said for years now that we should be looking at NFV only as an application of “carrier cloud”, and it is the recognition of the broader business of carrier cloud that will probably have to lead to container adoption. Perhaps, to NFV success as well.