When I did my blog yesterday on the problems with the ETSI ZTA software architecture, I had a number of emails asking how you could do lifecycle management using state/event principles. They showed me that one problem we have in coming to a good consensus on ZTA software is the general lack of understanding on how to view “lifecycles” in event terms.
I built the original ExperiaSphere project in Java based on Service Factories, state/event, and componentized data models, and the same principle was used to define the second stage of the project, documented in a series of PowerPoint presentations. You can get a specific and detailed explanation of what I’ll go over in this blog by reviewing THIS presentation.
Peoples’ questions showed that most think of a service as being something you “deploy” in a step, then manage by fielding any faults that come along. This is an intrinsic retreat to the functional view, and the way my email contacts suggested I reverse it is to explain how you do state/event processing of a simple lifecycle. I’ll do that, but to make it work I need to set the stage in a FIGURE.
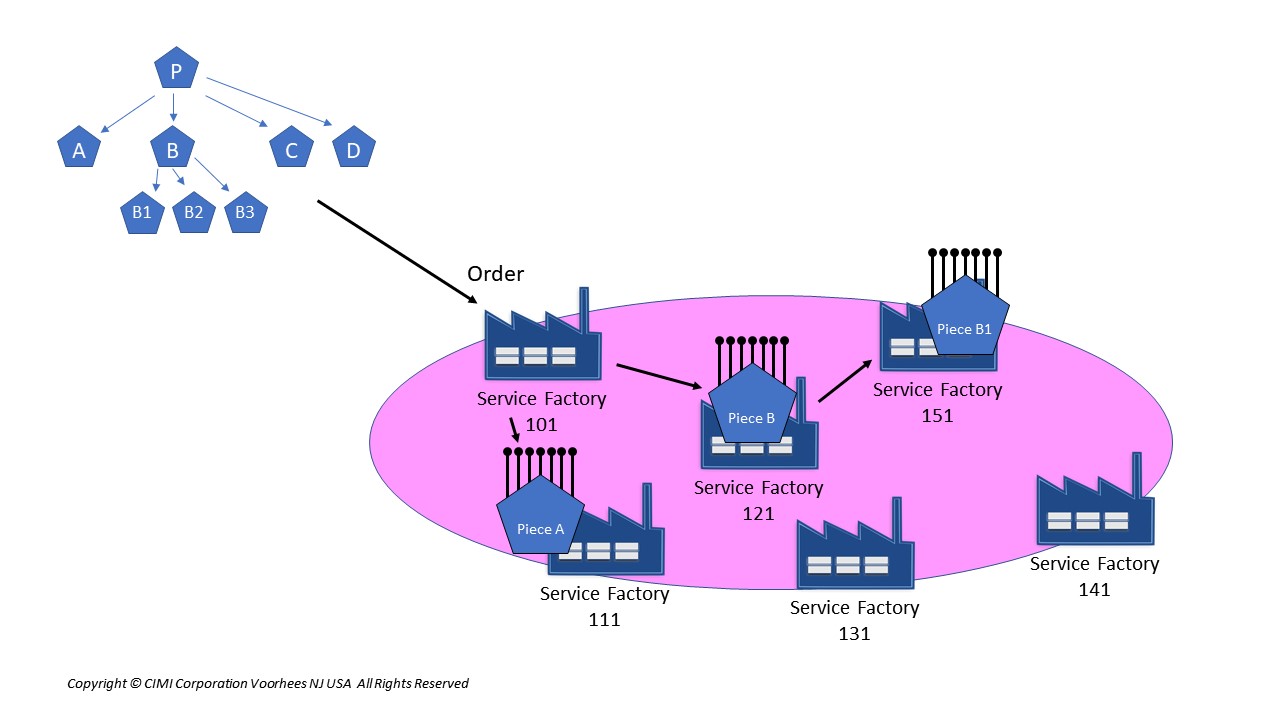{kind=link}
In this figure, we see a service order describing the service as a series of intent models (the pentagons). We also see a provider network “oval” and within it a series of “Service Factories” where the logic to associate events with a service model is hosted. The Factories contain the necessary code to parse/decompose the data model itself, and also to pass events within the model.
The service data model is a structure that holds service data, either fixed or inherited from the service order, and also the structural relationship between intent-modeled service components. Each component of a service (the lettered pentagons in the figure) is an intent model, and each intent model can contain either a deeper hierarchical structure (as the “B’s” to in the figure) or actual resource commitments. Each component has an SLA that it administers internally, and each is responsible for generating an event only to superior/subordinate elements, to coordinate changes in overall state.
When an order is taken, the order entry process will withdraw a standard blank order template for the service and populate it with service-specific data. The instance of the service data model is then created and stored in a repository, and all the intent models within it are in the “Ordered” state. A primary factory (here, Factory 101) is assigned, and an “Activate” event sent to Factory 101 referencing the order. Factory 101 then retrieves the order instance from the repository.
Within the “P” element is a state/event table, and that table defines an entry for the Activate event in the Ordered state. This entry would point to the logic needed for “primary decomposition” of the data model. This decomposition would take place based on the location where the service is to be delivered, for example, and it identifies that the “A” and “B” components of the service are actually needed here. That logic, in our example, identifies that components “A” and “B” are needed, and it then assigns factories to each (Factories 111 and 121, respectively) and dispatches an Activate to each, again referencing the service order and element.
Factory 111 has all it needs, and so it decomposes its “A” object to direct provisioning. Factory B has a choice of sub-elements (B1 through B3) and decides that B1 is what it needs, so it then sends an Activate to Factory 151 referencing Element B1 of the order instance. The B1 element is decomposed there, and it yields the deployment logic for that component. As each of the subordinate factories completes its task, it changes its state from Ordered to Active, and it generates an event to the superior object and factory, signaling “Active”, which then changes the state of the superior element to Active. This rolls back to the primary “P” element, which then reports the service as active.
Now let’s assume we have a fault condition within the domain of Factory 151, where the responsibility for the B1 service element resides. Factory 151 deployed infrastructure as a result of decomposing B1, and since B1 is intent-modeled, that infrastructure is responsible for meeting its SLA or reporting a fault. Thus, if the problem that occurs can be addressed within B1, nothing has to happen outside. If the fault cannot be corrected internally, then a “Fault” event is generated for B1 for this service. In theory, that fault could be handled by any Factory, but let’s assume it’s handled by the one that deployed it (which is likely in most cases).
Factory 151 then processes a Fault, it sets B1 into the Fault state, and it then reports a Fault to its parent component “B”, which you’ll recall is handled by Factory 121. That factory can then undertake whatever conditions would be suitable to correct things. For example, it could generate a “Teardown” to B1, restoring it to the Ordered state, and reactivate it. It could also decide (if possible) to deploy an alternative configuration like B2 or B3, sending an Activate to the selected component at one of the other Factories.
Every service condition here is an event. Every event is associated with a given service/element, and its data model has a state/event table that identifies the process that’s to handle that particular combination. The processes can all be stateless because all the data associated with the service is recorded in its record in the repository, which includes everything that every process did or needs, for every component of the service.
There are some important points to note here:
- There is a single common repository for the service data model for each instance of each service. That repository is used to prepare a Service Factory to process an event, so any service factory can in theory be given any event to process. In practice, you’d probably pick a factory near where the actual deployment was taking place.
- Both Service Factory processes (which just run the state/event tables) and the processes at each state/event intersect can be stateless, spun up where needed and as often as needed. The model is fully scalable.
- Decomposition of a model, the base process for a Service Factory, is service-independent. It just parses the data model and gets the proper service element to use in state/event processing.
- Activation, meaning deployment, like every other service lifecycle process, is simply the process associated with a specific state/event intersection. You could, in theory, specialize a process to one service, generalize it to a specific event, or whatever.
- The functional logic that’s defined in a model like NFV or ZTA is distributed through the state/event descriptions, not monolithic.
The “Service Factory” software element here is specialized to the decomposition of the model structure. The rest of the software can be whatever works. Every service model could have its own software processes at the state/event intersections. Vendors or third parties could provide pre-packaged services complete with the necessary software. Standardization is needed only at the level of the Service Factory and the mechanism for event connection to the proper services/processes.
Functionally, this structure could conform to the ETSI ZTA model, or the ETSI NFV E2E model, but it doesn’t impose an old software approach on a problem that should be solved with state-of-the-art thinking. This is the approach I tested out in the first ExperiaSphere project, done in connection with the TMF’s Service Delivery Framework activity. The lessons I learned in the implementation are the basis for the later ExperiaSphere framework presentations I referenced here.
My point in all of this is that this is the right way to do any network software, because networking is event-driven and because the implementation has to be resilient, scalable, and based on intent-modeled discrete elements, any implementation of which can serve the overall service needs equally. This is what the ZTA people need to do now, what the NFV people should have done. It’s probably too late for that second group, but not for the first, and because ZTA is so broadly critical I think the ETSI activity needs to take a second look at the architecture.